

Imagine losing sales every minute your site is down. That’s the reality for businesses without proper uptime monitoring. You work hard to build your online presence, but a single outage can undo all that effort and drive customers to competitors.
Uptime monitoring is your 24/7 watchdog that checks if your website or app is available. It alerts you the second something goes wrong, so you can fix it fast. No more guessing if your site is up or waiting for customer complaints.
What is Uptime Monitoring and Why You Need Website Availability Checks
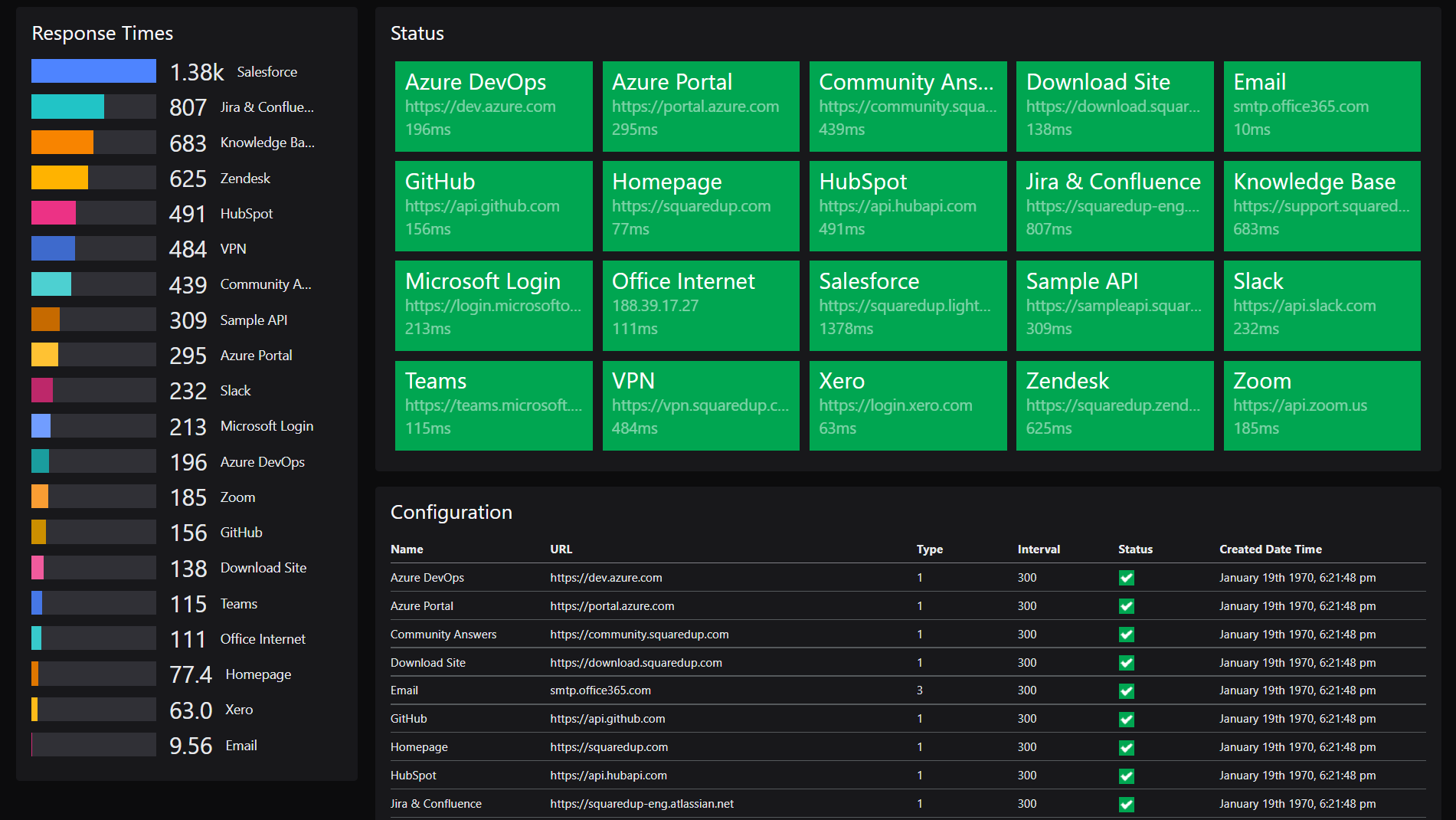
Uptime monitoring constantly tests your service using methods like HTTP requests, pings, or port checks. Tools like Pingdom, UptimeRobot, and Better Stack run these checks from multiple global locations to avoid false alarms. They verify your server responds correctly and within expected time limits.
When a failure is detected, the system sends instant alerts via email, SMS, Slack, or PagerDuty. This allows your team to respond before customers even notice. Detailed logs help you track performance over time and prove SLA compliance to clients.
Without monitoring, you rely on manual checks or customer reports, which is slow and unreliable. Automated downtime detection catches issues within seconds, protecting your revenue and reputation. For most small businesses, a budget-friendly SaaS tool like UptimeRobot or Pulsetic works great, costing as little as $10 per month.
Always On: The Vital Role of Uptime Monitoring in 2026
In today’s digital-first world, your online services must be available every second. Uptime monitoring is the constant, automated check that ensures your websites, servers, and APIs are working correctly. It’s not just about fixing problems; it’s about preventing them before they cost you money or damage your brand’s standing.
Think of it as a vigilant security guard for your digital assets. This practice is essential for maintaining customer trust, keeping your search engine rankings high, and ensuring smooth business operations. By catching issues early, you protect revenue and reputation.
| Check Type | Purpose |
|---|---|
| HTTP/HTTPS | Verifies website and service responsiveness. |
| ICMP (Ping) | Confirms basic network connectivity. |
| TCP/UDP Port | Ensures specific network services are accessible. |
| DNS | Validates domain name resolution. |
| Heartbeat/Cron | Monitors background processes. |
Real-Time Website Availability Monitoring
Your website’s availability is its first impression. Real-time monitoring continuously probes your site from multiple global locations. This ensures that when a customer visits, the page loads quickly and correctly. It’s about providing a seamless user experience, every single time.
Read also: Proxys Premium That Actually Work in 2026
These checks simulate actual user visits, confirming that not just the server is up, but that the entire web page is functioning as expected. This level of detail is crucial for customer satisfaction and business continuity.
Downtime Detection and Instant Alerts

When an outage occurs, every minute counts. Advanced uptime monitoring systems detect failures instantly. They then send immediate alerts to the right people. This rapid notification is key to minimizing downtime and its impact.
Rapid detection and alerting are the cornerstones of effective incident management. They transform potential crises into manageable issues.
Alerts can be sent via SMS, email, Slack, or other preferred channels. This ensures your team is aware of a problem the moment it happens, allowing for swift resolution.
Server Status Checks for Proactive Maintenance
Servers are the backbone of your online presence. Regular server status checks go beyond just seeing if a server is ‘on’. They monitor key performance indicators like CPU usage, memory, and disk space.
Read also: Argentina proxy: stop wasting time on free slow IPs
This proactive approach helps identify potential issues before they cause a full outage. It allows for planned maintenance, preventing unexpected downtime and ensuring optimal performance. This is a core part of site reliability engineering (SRE).
API Monitoring for Reliable Integrations
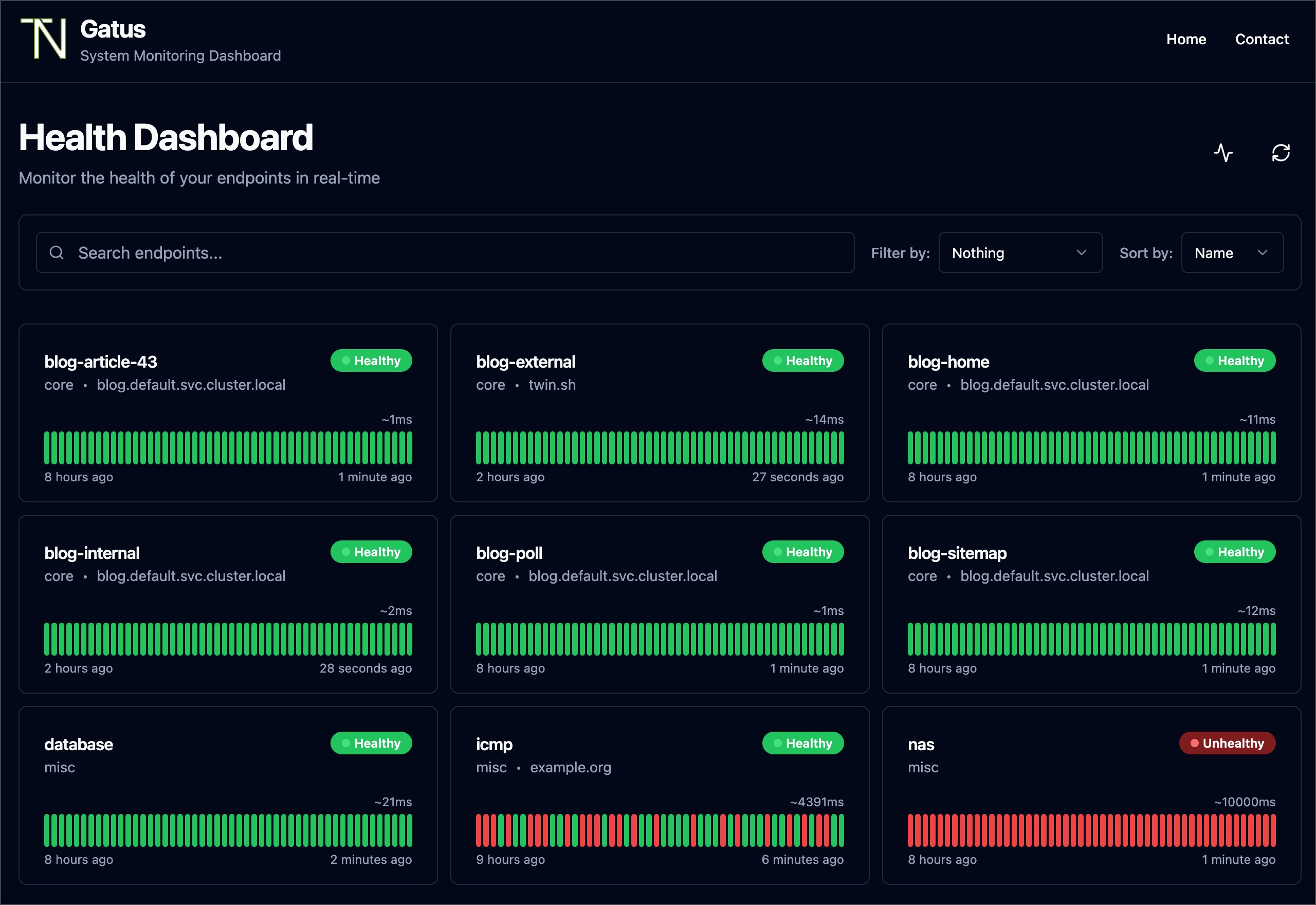
In 2026, many services rely on APIs for communication. If your API goes down, connected applications and services fail. API monitoring verifies that these critical communication channels are functioning correctly and responding within acceptable timeframes.
It ensures that data flows smoothly between different software systems. This prevents disruptions in services that depend on these integrations, safeguarding the entire ecosystem. This is vital for network uptime.
Performance Monitoring to Optimize Speed
Uptime is not just about being online; it’s about being fast. Performance monitoring tracks how quickly your services load and respond. Slow performance can drive users away just as effectively as a complete outage.
By analyzing response times and identifying bottlenecks, you can optimize your website and applications. This leads to a better user experience and improved conversion rates. It’s a key aspect of overall service monitoring.
Network Uptime Tracking for Business Continuity
Your network infrastructure is critical for keeping services accessible. Tracking network uptime ensures that routers, switches, and firewalls are all functioning correctly. Any network issue can cascade into service failures.
Maintaining high network uptime is essential for uninterrupted business operations. It guarantees that your users can consistently reach your services without interruption. This is fundamental for business continuity.
Cron Job Monitoring to Prevent Failures
Many essential background tasks run on schedules, often managed by cron jobs. If these jobs fail silently, critical processes can halt without anyone knowing. Cron job monitoring ensures these scheduled tasks are completing successfully.
This type of monitoring acts as a safety net for automated processes. It prevents data corruption or service degradation caused by missed or failed background operations. It’s a specific form of uptime monitoring that is often overlooked.
Synthetic Monitoring for User Experience Testing
Synthetic monitoring goes a step further than basic checks. It simulates complex user journeys through your website or application. This allows you to test specific workflows and interactions from an end-user’s perspective.
Synthetic monitoring provides a realistic view of how real users experience your service, catching issues that simple checks might miss.
This advanced form of testing is crucial for ensuring a high-quality user experience. It helps identify issues in critical user paths, like completing a purchase or signing up for a service.
The Future of Uptime Monitoring in 2026
Uptime monitoring in 2026 is more sophisticated and integrated than ever. We see a strong trend towards observability platforms that combine uptime checks with deeper performance and error tracking. The focus is on preventing issues before they impact users, not just reacting to them.
Solutions are becoming more intelligent, using AI to predict potential failures and reduce alert fatigue. The integration with incident management workflows is seamless, making site reliability engineering more accessible. Expect continued innovation in synthetic transaction monitoring and proactive health checks.
Read also: Need to buy residential IP proxy? Here’s the cheapest option in 2026
Your 3-Step Action Plan for Uptime Monitoring
Step 1: Define Your Critical Services
List every website, API, and server that directly impacts your revenue or user experience. Prioritize services that, if down, would cause immediate customer complaints or lost sales.
Step 2: Choose Your Monitoring Tool
For most businesses, a SaaS platform like UptimeRobot or Better Stack offers the best balance of cost and ease. If you have technical staff and want full control, consider self-hosting with Uptime Kuma.
Step 3: Configure Alerts and Escalation
Set up instant alerts via SMS or Slack for critical failures, and add a second tier (email or phone call) if the first alert isn’t acknowledged. Test your alerting workflow monthly to ensure no one sleeps through an outage.
Frequently Asked Questions
What is the difference between a ping check and an HTTP check?
A ping check verifies basic network connectivity to a server, while an HTTP check confirms that a web server is responding with the correct status code. For websites, always use HTTP checks to ensure the application layer is healthy.
How often should I monitor my services?
For most production services, a check interval of 5 minutes is sufficient to catch outages quickly without overwhelming your infrastructure. For revenue-critical systems, consider 1-minute intervals.
What is a synthetic transaction monitor?
It simulates a real user journey, like logging in or completing a purchase, to verify end-to-end functionality. This goes beyond simple uptime checks and catches errors that don’t cause a full outage.
Investing in uptime monitoring is not optional; it is the guardrail that protects your digital reputation and bottom line. By following the action plan above, you ensure your services remain reliable and your users stay satisfied.
Start by signing up for a free tier of a monitoring tool today and configure your first check in under ten minutes. The peace of mind you gain is worth far more than the small effort required.
Imagine a dashboard where every service glows green, and your team receives alerts only for genuine issues—never false alarms. This is the future of proactive infrastructure management, and it is within your reach right now.